概述
这里主要是介绍下企业直投广告中的几个环节(广告监测、归因处理及转化回传)的业务逻辑,遇到的问题以及解决方案。
之前听过马师傅的“接化发”三字诀,觉得也可以套用到广告投放上,因此这次就按这个路子来说下。
接:广告监测
所谓“接”,当然就是接收广告投放相关的数据了。企业在媒体平台投放广告后会要求媒体将点击广告的用户信息及广告信息上报回来。
这么做的目的大致有如下几个:
- 做基础统计,以作为结算依据
- 采集用户信息,结合站内数据进行人群分析
- 记录广告投放效果,以便于在定向和素材等方面进行迭代
其中第一点的作用不是那么重要,因为我们不是简单采用CPM或CPC方式进行结算,多是以投放效果(CPA)结合CPM的方式来计算投放的费用。效果数据的收集也可以通过应用下载时的deeplink来做到(这点有机会再展开说)。
媒体通常会采用HTTP请求的形式上报广告数据。上报的数据前期主要为广告的曝光、点击等信息。后来随着视频广告的占比逐渐加大,上报的数据中也多了有效播放数据(通常默认播放时长超过3秒为有效播放)。在我们收到的数据里,曝光/播放/点击三种数据的比例大致为:60:20:1。其中曝光数据的作用不是很大,主要用来对RTA的效果进行评估。需要认真处理的是点击数据和有效播放数据,这两种数据会被用来做归因处理。
在广告监测这个环节我们遇到了两个问题:
- 每个媒体上报的数据格式不一样,要统一有点儿困难
- 上报数据规模较大,产生了存储压力
对于第一个问题,我刚接手的时候看到的做法是为每个媒体分别创建了一个处理器来解析处理相关的请求。这种思路在早期是没问题的,甚至可以说是相当健壮也相对容易维护的一种方案。但是随着业务的发展,我们截止现在陆续对接了大大小小近五十个媒体。照说再写几十个处理逻辑也不是什么难事,关键一些大的媒体,比如头条百度腾讯,在这些媒体不同的子平台上也会有不同的投放需求,这样原来方案扩展性较差的问题就凸显出来了。对于前者,我们设计了灵犀平台,实现了不同媒体的在线配置对接。对于后者,我们在媒体的基础上又抽象出了监测维度,来适配同一媒体不同子平台的投放需求。
再来说第二个问题,我们接收的三种数据的总量一度达到了每天3.2亿,六个节点承接了3700QPS的访问。这个规模其实也不大,加之我们只是简单的接收数据,不需要返回什么内容,因此依托Nginx的轮询(RoundRobin)方案就可以完美承接下来。困难的是数据的存储:其中曝光数据只是用来做离线统计分析,直接通过Kafka扔到HDFS就可以了;剩下的点击和有效播放数据,因为还需要用来支撑归因和场景回放等业务,得分别存储到Redis和MySQL数据库中。好在这部分数据只需要按业务需求存储一定周期内的部分即可。但是随着后来视频广告占比增多,上报的有效播放数据骤增,redis和mysql先后出现了报警:redis空间使用率一度高达93%,mysql存储的相关数据达到了1.2T,并引发了主从同步的问题,甚至还影响了同一MySQL集群上其他团队的业务。解决redis存储问题的方案比较简单,只是精简了存储的内容并适当调整业务逻辑就将空间使用量压缩到了37%(就是这么简单)。对mysql这边尝试了几次调整后发现效果不大,最终是将数据移到了HBase,在MySQL中只存储了高度精简的数据来支持已有的业务查询,同时MySQL表还可以作为HBase表的二级索引。这样调整后的架构至少可以支撑当前业务总量的2.5倍压力,能够轻松较长的一段时间了。
化:归因处理
“化”可以理解为消化或者化为己用。归因的主要作用就是消化投放相关的数据,为投放提供助力。
和广告圈子之外的人聊归因这块儿业务时,常会被问一个问题:“什么是归因?”。我的解释是:归因可以简单理解为“找到原因”或者说“溯源”,在广告投放上就是找到一个投放效果(比如说安装APP)具体是由哪个广告带来的。为完成归因处理我们需要两种数据:
- 点击/有效播放数据(广告投放数据)
- 用户应用日志(记录了效果数据)
归因处理的核心逻辑就是用应用日志中的设备ID来和存储的点击数据中的设备ID进行匹配,匹配上了就说明归因成功。因为我们主要是做拉新归因,所以在执行归因之前还会根据设备ID判断下是不是历史用户。
归因匹配的方式有两种:精准归因和模糊归因。精准归因就是使用设备ID做匹配,模糊归因则是在拿不到设备ID时候采用的折中方案,是用IP加设备的一些基础信息(比如系统版本号)做匹配。因此在常规操作时,模糊归因的时间窗口要远小于精准归因。根据我们的评估,1小时是模糊归因的最佳窗口,超过2小时就会暴露类似撞库的问题,更遑论3天了。精准归因的时间窗口通常是72小时。
归因的模型我们使用的是Last Click模型,这也被称为末次互动模型,是最为通用且最容易实现的模型。不过,我们也有尝试离线做过助攻模型(也称时间衰减模型),即一个用户在最终下载应用前浏览或点击过多个广告,虽然用户并没有通过这些广告产生下载行为,但我们也认为这些广告对用户是有影响的,并根据距离用户下载行为时间点的远近给这些广告一个权重。
在归因这块儿给我们带来过的最大困扰是用户应用日志的规模。早期的归因引擎处理的是全量原始访问日志,每小时100多G的日志给业务处理以及网络都带来了巨大的压力。在归因场景上其实不需要处理这么细粒度的数据——除了某些特殊的转化事件,通常只需要拿到用户的设备ID、事件时间等几个维度的数据就可以了。据此我们增加了用户日志的标准化加工和去重处理服务(也可以称作ETL服务),最终将归因日志的规模压缩到了原来的1/80左右。用户日志压缩带来的好处是显而易见的:首先运维频繁吐槽的网络问题没有了;其次归因转化处理的效率得到了显著地提升;最后日志占用空间小了,可以保存更长的时间,有助于问题的重现和测试。我们还利用这个日志ETL服务产出了另外一些数据,来支撑用户应用日志相关的其他业务,比如转化回传。
发:回传转化
在这个环节我们会把前面两个环节消化的数据“发”给媒体。转化回传的作用就是将归因结果及后续的转化事件回传给媒体,帮助媒体优化广告模型,提升投放效果。
这块儿遇到的第一个问题还是如何gracefully实现不同媒体要求的各种请求格式。因为回传的数据格式较之监测复杂太多,肯定是要为相当一部分媒体编写独立逻辑的。但是也需要为回传格式相对简单的媒体提供一个统一的解决方案。为此,我们实现了一个转化回传处理引擎,通过一行配置规则就能组合出大部分的回传数据,如下是一行配置示例:
|
1 2 3 4 5 6 7 |
a_type=@retain_1day&sign=$md5($addParams($rmParams(#clk.callbackUrl,@sign),a_type=@retain_1day),#clk.openudid) 这个规则的处理说明: 1. 删除点击记录中存储的回调路径中的sign参数 2. 在回调路径中添加a_type参数,参数值为:retain_1day 3. 使用修改后的回调路径和点击中的openudid进行md5运算,作为回调签名(sign) 4. 将sign和a_type加到回调路径中 |
就这样通过配置规则与独立逻辑的组合最终实现了个性化与灵活性的统一。
回传这块儿遇到的第二个问题是在拉活回传的时候经常会出现用户日志早于点击请求到达的现象,因为我们有根据设备ID对用户日志做布隆过滤,这样就会导致相当一部分用户漏传。解决方案也相对简单:使用Kafka Consumer的pause()和resume()方法做下延迟消费就可以了——毕竟媒体对转化回传的实时性要求不强。
综述
以上就是直投的监测归因回传三个核心模块,对应的数据流图如下:
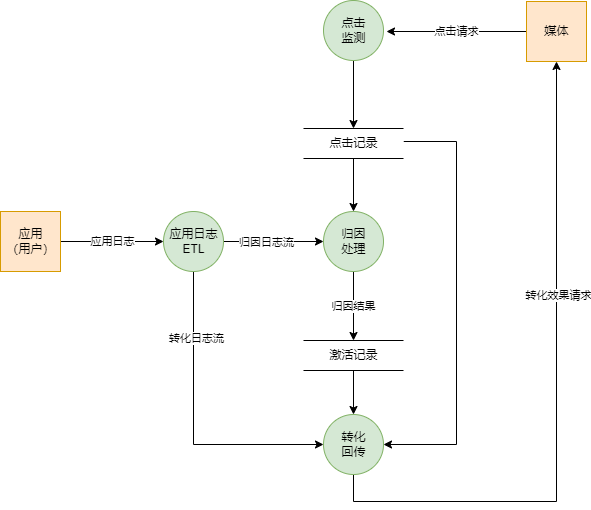
在广告直投的业务中除了之外还有素材加工,商品库生成,报表等内容,下图是我们直投各个业务模块的一个示意:
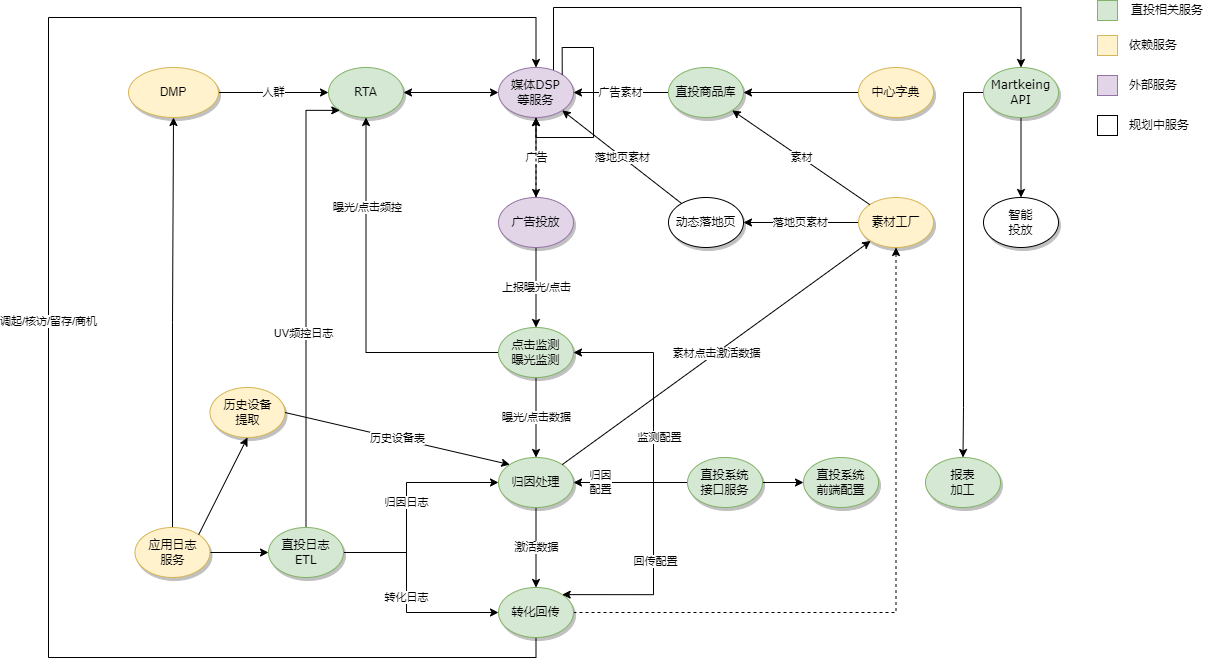
大体上就是这样。
其他
这篇东西在去年的这个时候就已经起好标题,并写了大概四分之一的内容——再之后就搁置起来了…
时间匆匆过去,估计很多人应该都已记不得马老师,更遑论“接化发”三字诀,幸好我还记得这个拖延了好久的计划,恰好最近也忽然多了许多时间,就趁写交接文档的时候一并完成了
发表评论